As your Next.js application scales, your app directory can quickly transform from a neat list of pages into a complex maze of folders.
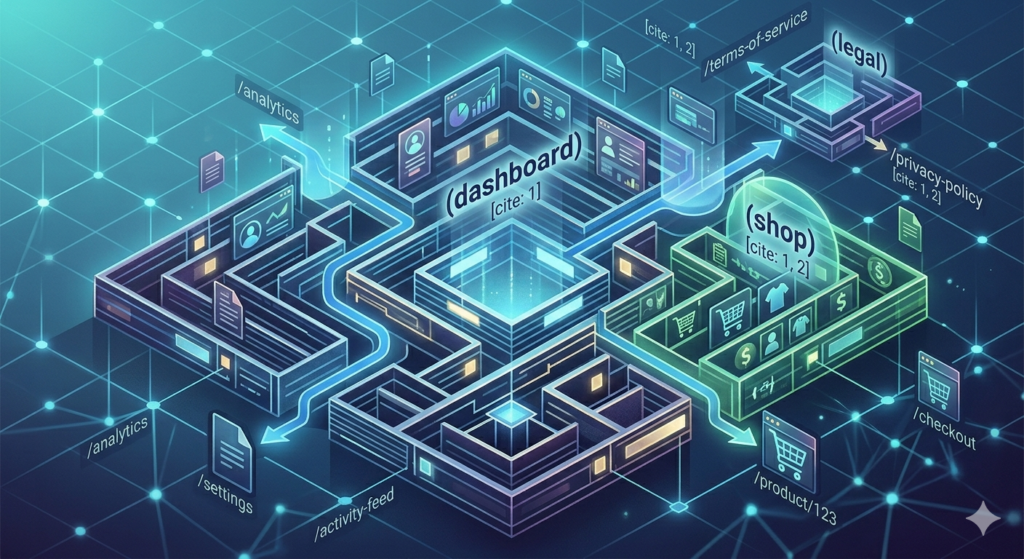
You might find yourself wanting to organize files by feature or intent—like grouping all “Auth” pages together—without those folder names actually appearing in your website’s URL.
This is exactly where Route Groups come in.
They allow you to wrap folders in parentheses, signaling to Next.js: “Organize these files here, but keep this folder out of the URL.”
The Anatomy of a Route Group
To create a route group, you simply wrap a folder name in parentheses: (folderName).
-
Standard Folder:
app/marketing/about/page.tsx→ URL:/marketing/about -
Route Group:
app/(marketing)/about/page.tsx→ URL:/about
By using (marketing), you’ve grouped your marketing-related routes for your own sanity, but the end user never sees the word “marketing” in their browser bar.
Why Use Route Groups?
Beyond just keeping your files tidy, route groups unlock powerful architectural patterns:
1. Logical Organization
The most common use case is simply grouping related routes (e.g., (auth), (dashboard), (shop)) so they aren’t scattered alphabetically throughout your root app folder.
2. Creating Multiple Root Layouts
Usually, Next.js expects one top-level layout.tsx in the root of the app directory.
However, what if your marketing site needs a standard navbar, but your user dashboard needs a completely different sidebar and no navbar at all?
By moving your routes into separate groups, you can give each group its own Root Layout.
-
app/(marketing)/layout.tsx(Applies to all marketing pages) -
app/(dashboard)/layout.tsx(Applies to all dashboard pages)
Note: When you opt for multiple root layouts, the top-level
app/layout.tsxis removed. Each root layout must then include its own<html>and<body>tags.
3. Opting-in to Shared UI
You might want a specific set of routes to share a layout while others don’t. For instance, you could have (shop)/layout.tsx that provides a persistent shopping cart view for all routes inside that folder, while your (legal) group remains a clean, distraction-free layout for Terms of Service and Privacy pages.
Essential Rules to Remember
-
URL Neutrality: The name of the group (e.g.,
(marketing)) is completely omitted from the URL path. -
Naming Collisions: Be careful! Since the group name is ignored,
app/(groupA)/about/page.tsxandapp/(groupB)/about/page.tsxwill both resolve to/about, causing a build error. -
Nested Groups: You can nest route groups within each other if your project is particularly massive, though usually, one level is enough for most apps.
Feature Comparison
Feature: Regular Folder vs. Route Group
Visible in URL: Yes (Regular) | No (Route Group)
Can have a Layout: Yes (Regular) | Yes (Route Group)
Purpose: Path Definition (Regular) | Organization & Layout Isolation (Route Group)
Special Syntax: folder (Regular) | (folder) (Route Group
Conclusion
Route Groups are a “quality of life” feature that separates your file-system architecture from your public URL structure.
Whether you’re trying to isolate a specific layout or just want to group your “Admin” tools together without cluttering your URLs, route groups provide the flexibility to build a scalable, maintainable Next.js application.
Quote of the Day:
“For every minute spent organizing, an hour is earned.” — Benjamin Franklin
Useful links below:
Let me & my team build you a money making website/blog for your business https://bit.ly/tnrwebsite_service
Get Bluehost hosting for as little as $1.99/month (save 75%)…https://bit.ly/3C1fZd2
Best email marketing automation solution on the market! http://www.aweber.com/?373860
Build high converting sales funnels with a few simple clicks of your mouse! https://bit.ly/484YV29
Join my Patreon for one-on-one coaching and help with your coding…https://www.patreon.com/c/TyronneRatcliff
Buy me a coffee  https://buymeacoffee.com/tyronneratcliff
https://buymeacoffee.com/tyronneratcliff